













I hate benchmarking code, just like any human (which, at this point, most viewers of this probably aren’t ¯_(ツ)_/¯). It is much more fun to pretend that your caching of a value increased performance 1000% rather than testing to see what it did. Alas, benchmarking in JavaScript is still necessary, especially as JavaScript is used (when it shouldn’t be?) in more performance-sensitive applications. Unfortunately, due to many of its core architectural decisions, JavaScript doesn’t make benchmarking any easier.
What is wrong with JavaScript?
The JIT compiler decreases accuracy(?)
For those unfamiliar with the wizardry of modern scripting languages like JavaScript, their architecture can be pretty complex. Instead of only running code through an interpreter that immediately spits out instructions, most JavaScript engines utilize an architecture more similar to a compiled language like C—they integrate multiple tiers of “compilers”.
Each of these compilers offers a different tradeoff between compilation time and runtime performance, so the user doesn’t need to spend compute optimizing code that is rarely run while taking advantage of the more advanced compiler’s performance benefits for the code that is run most often (the “hot paths”). There are also some other complications that arise when using optimizing compilers that involve fancy programming words like “function monomorphism”, but I will spare you and avoid talking about that here.
So… why does this matter for benchmarking? Well, as you might have guessed, because benchmarking is measuring the performance of code, the JIT compiler can have a pretty big influence. Smaller pieces of code, when benchmarked, can often see 10x+ performance improvements after full optimization, introducing a lot of error into the results. For example, in your most basic benchmarking setup (Don’t use anything like the below for multiple reasons):
for (int i = 0; i<1000; i++) {
console.time()
// do some expensive work
console.timeEnd()
}
(Don’t worry, we will talk about console.time too)
A lot of your code will be cached after a few trials, decreasing the time per operation significantly. Benchmark programs often do their best to eliminate this caching/optimization, as it can also make programs tested later in the benchmark process appear relatively faster. However, you must ultimately ask whether benchmarks without optimizations match performance in the real world. Sure, in certain cases, like infrequently accessed web pages, optimization is unlikely, but in environments like servers, where performance is most important, optimization should be expected. If you are running a piece of code as middleware for thousands of requests a second, you better hope V8 is optimizing it.
So basically, even within one engine, there are 2-4 different ways to run your code with varying different levels of performance. Oh, also, it is incredibly difficult in certain cases to ensure certain optimization levels are enabled. Have fun :).
Engines do their best to stop you from timing accurately
Ya know fingerprinting? The technique that allowed Do Not Track to be used to aid tracking? Yeah, JavaScript engines have been doing their best to mitigate it. This effort, along with a move to prevent timing attacks, led to JavaScript engines intentionally making timing inaccurate, so hackers can’t get precise measurements of the current computers performance or how expensive a certain operation is. Unfortunately, this means, without tweaking things, benchmarks have the same problem.
The example in the previous section will be inaccurate, as it only measures by millisecond. Now, switch that out for performance.now(). Great, Now we have timestamps in microseconds!
// Bad
console.time();
// work
console.timeEnd();
// Better?
const t = performance.now();
// work
console.log(performance.now() - t);
Except… they are all in increments of 100μs. Now let’s make add some headers to mitigate the risk of timing attacks. Oops, we still can only 5μs increments. 5μs is probably enough precision for many use cases, but you will have to look elsewhere for anything that requires more granularity. As far as I know, no browser allows for more granular timers. Node.js does, but of course, that has its own issues.
Even if you decide to run your code through the browser and let the compiler do its thing, clearly, you will still have more headaches if you want accurate timing. Oh yeah, and not all browsers are made equal.
Every environment is different
I love Bun for what it has done to push server side JavaScript forward, but dang, it makes benchmarking JavaScript for servers a lot harder. A few years ago, the only server side JavaScript environments people cared about were Node.js and Deno, both of which used the V8 JavaScript engine (the same one in Chrome). Bun instead uses JavaScriptCore, the engine in Safari, which has entirely different performance characteristics.
This problem of multiple JavaScript environments with their own performance characteristics is relatively new in server-side JavaScript but has plagued clients for a long time. The 3 different commonly used JavaScript engines, V8, JSC, and SpiderMonkey for Chrome, Safari, and Firefox, respectively, all can perform significantly faster or slower on an equivalent piece of code.
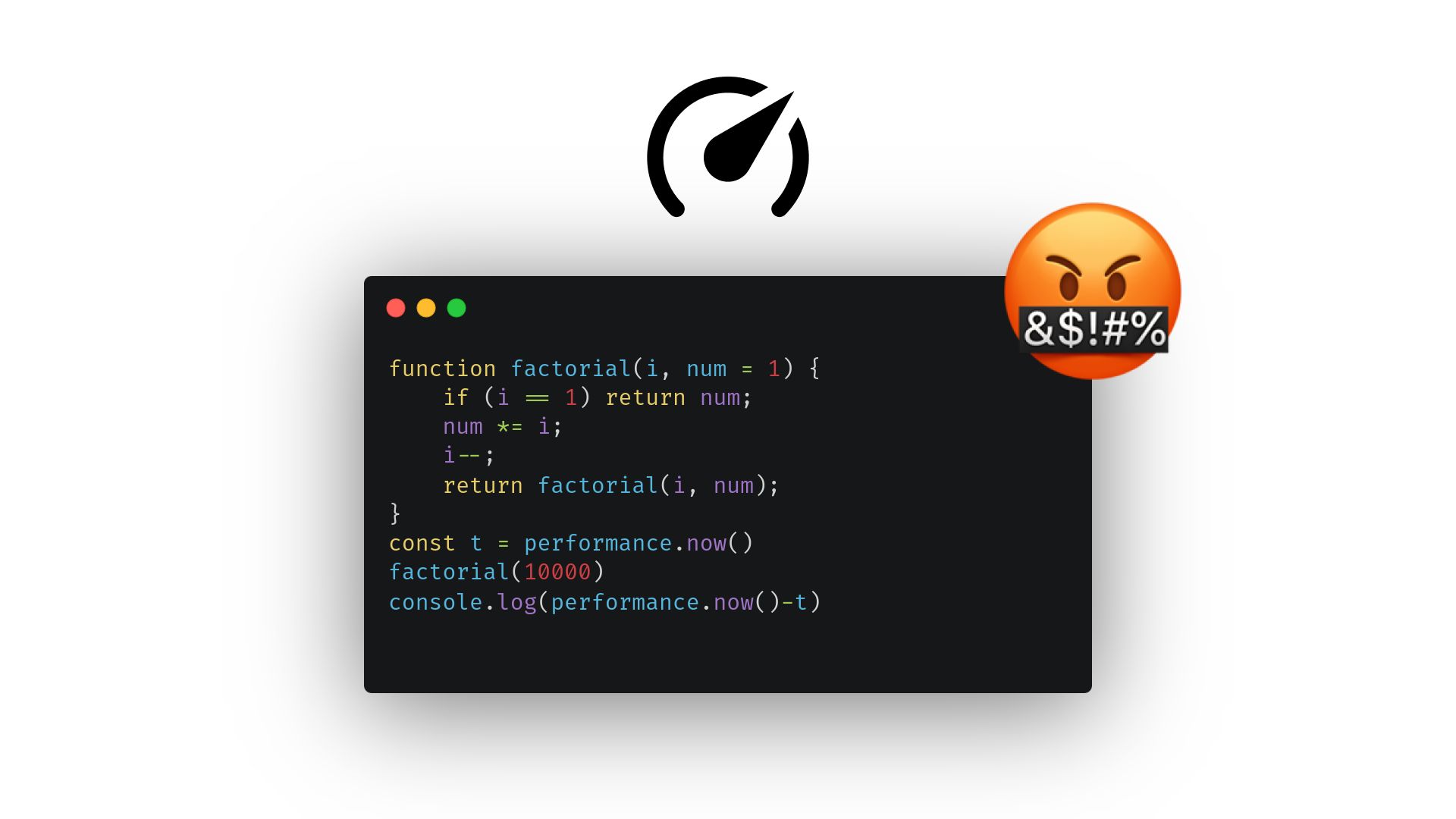
One example of these differences is in Tail Call Optimization (TCO). TCO optimizes functions that recurse at the end of their body, like this:
function factorial(i, num = 1) {
if (i == 1) return num;
num *= i;
i--;
return factorial(i, num);
}
Try benchmarking factorial(100000) in Bun. Now, try the same thing in Node.js or Deno. You should get an error similar to this one:
function factorial(i, num = 1) {
^
RangeError: Maximum call stack size exceeded
In V8 (and by extension Node.js and Deno) each time the factorial() calls itself at the end, the engine creates an entirely new function context for the nested function to run in, which eventually is limited by the call stack. But why doesn’t this happen in Bun? JavaScriptCore, that Bun uses, implements TCO, which optimizes these types of functions by turning them in to a for loop more like this:
function factorial(i, num = 1) {
while (i != 1) {
num *= i;
i--;
}
return i;
}
Not only does the above design avoid call stack limits, but it is also much faster because it doesn’t require any new function contexts, meaning functions like the above will benchmark very differently under different engines.
Essentially, these differences just mean you should benchmark across all engines that you expect to run your code to ensure code that is fast in one isn’t slow in another. Also, if you are developing a library that you expect to be used across many platforms, make sure to include more esoteric engines like Hermes; they have drastically different performance characteristics.
Honorable mentions
- The garbage collector and its tendency to pause everything randomly
- The JIT compiler’s ability to delete to all of your code because it “isn’t necessary”
- Terribly broad flame graphs in most JavaScript devtools
- I think you get the point
So… what is the solution?
I wish I could point to an npm package that solves all of these problems, but there really isn’t one.
On the server, you have a slightly easier time. You can use d8 to manually control optimization levels, control the garbage collector, and get precise timing. Of course, you will need some Bash-fu to set up a well-designed benchmark pipeline for this, as unfortunately d8 is not well integrated (or integrated at all) with Node.js. You can also enable certain flags in Node.js to get similar results, but you will miss out on features like enabling specific optimization tiers.
v8 --sparkplug --always-sparkplug --no-opt [file]
An example of D8 with a specific compilation tier (sparkplug) enabled. D8, by default, includes more control of GC and more debug info in general.
You can get some similar features on JavaScriptCore??? Honestly, I have not used JavaScriptCore’s CLI much, and it is heavily underdocumented. You can enable specific tiers using their command line flags, but I am not sure how much debug information you can retrieve. Bun also includes some helpful benchmarking utilities, but they are limited similarly to Node.js.
Unfortunately, all of this requires the base engine/test version of the engine, which can be quite hard to get. I have found that the simplest way to manage engines is esvu paired with eshost-cli, as they together make managing engines and running code across them considerably easier. Of course, there is still a lot of manual work required, as these tools just manage running code across different engines—you still have to write the benchmarking code yourself.
If you are just trying to benchmark on engine with default options as accurately as possible on the server, there are off the shelf Node.js tools like mitata that help improve timing accuracy and GC related errors. Many of these tools, like Mitata, can also be used across many engines; of course, you will still have to set up a pipeline like the above.
On the browser, everything is a lot more difficult. I don’t know of any solutions for more precise timing, and control of the engine is far more limited. The most information you can get relating to runtime JavaScript performance in the browser will be from the Chrome devtools, which offer basic flame graph and CPU slowdown simulation utilities.
Conclusion
Many of the same design decisions that made JavaScript (relatively) performant and portable make benchmarking significantly more difficult than it is in other languages. There are many more targets to benchmark, and you have much less control in each target.
Hopefully, a solution will someday simplify many of these problems. I might eventually make a tool to simplify cross-engine and compilation tier benchmarking, but for now, creating a pipeline to solve all of these problems takes quite a bit of work. Of course, it is important to remember these problems don’t apply to everyone—if your code is only running in one environment, don’t waste your time benchmarking other environments.
However you choose to benchmark, I hope this article showed you some of the issues present in JavaScript benchmarking. Let me know if a tutorial on implementing some of the things I describe above would be helpful.

{kind=link}